



Is Mesh Computing The Edge Everyone's Seeking?
Mesh means the edge is, well, everywhere


Edge computing never took off the way it was predicted.
The problem is scale - you cannot put a data center where the data resides when data resides - everywhere.
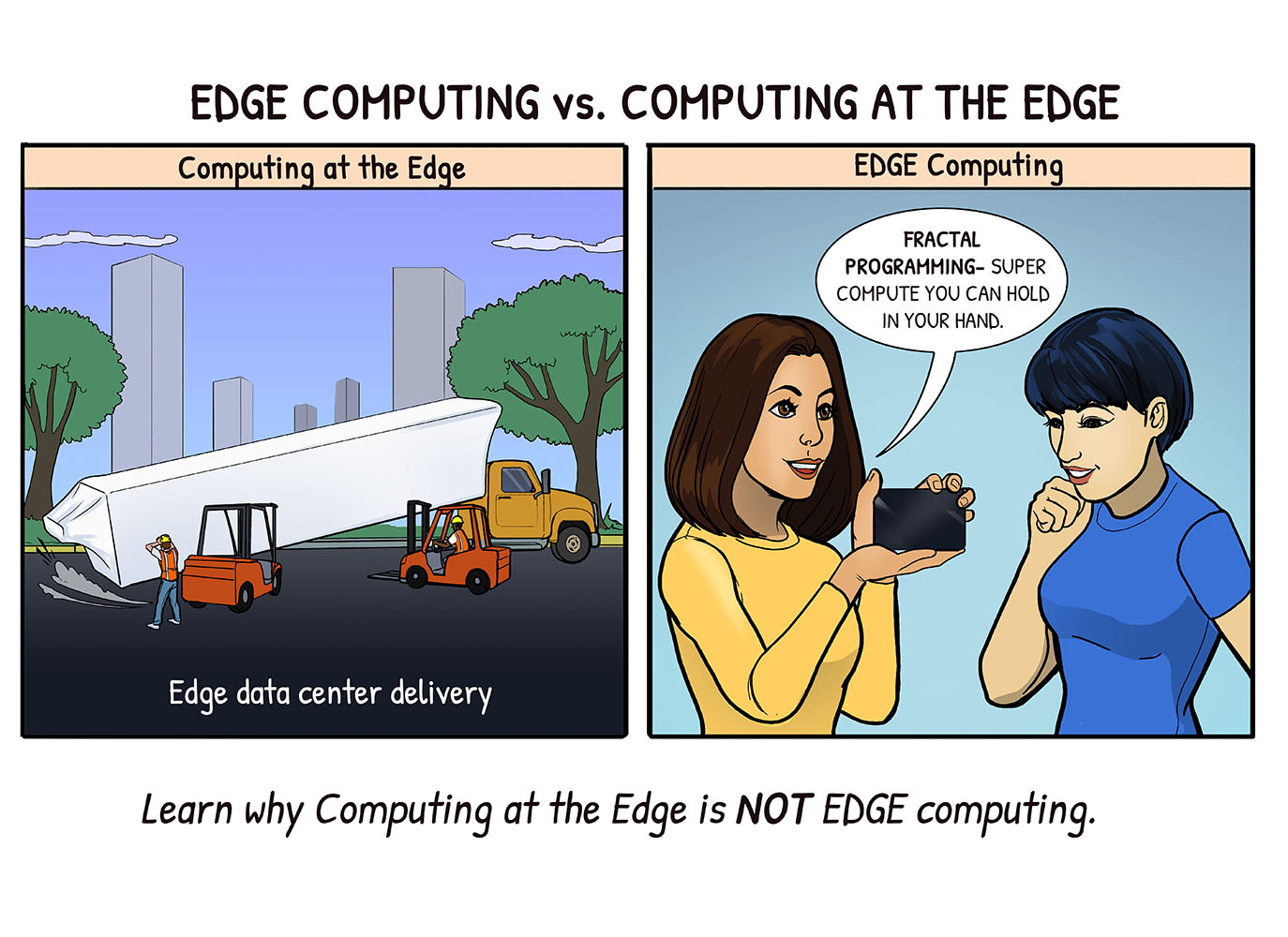
Edges are everywhere - about everything now has a data collecting edge - and there is no way hardware guys are going to put data centers - even little ones - everywhere.
Obsolete hardware companies came up with edge data centers - which coordinate smaller data centers in far flung, often scary places.
An edge data center is like heart-healthy cigarettes - pretty much a non-starter.
NOTE OUR NEW SUSTAINABLE COMPUTING SITE: THE SUSTAINABLE COMPUTING INITIATIVE - share with anyone who thinks America needs data centers.
If “it” requires a data center - and there are thousands, tens of thousands of “its,” one realizes how unscalable that model currently is.
The problem with edge computing is EDGES are proliferating faster than the computing to process them.
Four years ago when edge was first a thing, the idea was to run a few dozen locations, tie to a central cloud, do the processing and deliver edge computing.
IBM led this narrative - and like all IBM narratives, it was hardware-based and obsolete before IBM implemented its first system.
Here is an IBM press release: https://www.ibm.com/think/topics/edge-computing
If you read it carefully, what it does NOT say is one ought to compute at the edge - COMPUTE AT THE EDGE.
In the IBM model, collect data from IoT devices, servers, sensors and send data to a central processing unit - like a mainframe in a cloud.
Welcome to IBM and obsolete edge computing.
Let us introduce you to computing at the edge.
Those two statements are opposites - or antonyms if you are an English major - and their opposing concepts make all the difference in the world.
Since 4 years ago, the edge matured - data is now collected on wristwatches, devices on store shelves, and this month, our pals in the Chinese Government announced they are fielding drones the size of mosquitos - and thus one would gather they too are now an “edge” that collects data that needs to be part of this model.
IBM would love to put data centers on mosquitos but even their press team would not go that far.
If edges - computing edges, data gathering edges are everywhere - in IoT devices, in cars, on lamp posts, on oil rigs, on heavy equipment in office buildings - everywhere - how do you manage that mess?
Let’s talk architecture.
Centralized computing is 100% out - if you have ANY central point of control, you hit the showers because you are way too slow - think latency - to play in this game.
Central control means if the cloud or central data center goes down, game over.
Off go IBM, HP, Dell and all hardware vendors.
The first requirement is that computing is done where the data resides, not gathered from where the data resides. Let’s go there.
You have an oil drilling platform.
You have a satellite in low earth orbit targeting military assets.
You have 1 million IoT devices in homes in a metro area gathering heat pump data about home energy usage by the minute.
The first problem is the data size, the second is latency.
Data demands of current tech require a centralized data center or cloud - because current hardware architecture needs a big data center to do big things.
IBM and the hardware guys love that model - customers perhaps not so much.
Then there is latency - the seconds to minutes needed to reach a conclusion.
For an end-of-year financial report, minutes don’t matter.
For 24,000 orbiting satellites, running coordinates on military assets - the other guy’s assets, seconds mean life or death.
Thus the requirement of doing the compute where the data resides, not in someone’s cloud.
It’s the same thing for the oil rig.
Computing, or in this case super computing, on an oil rig to determine from billions of sensor-generated data points equipment is about fail is a big deal. Oil rigs are often in hard-to-reach locations - that’s why they make movies about oil rigs - which always end badly.
Computing where the data resides becomes a sine qua non - or if you did not take Latin, it’s “like you gotta have it.”
No conventional technology enables the massive computing where the data resides - without a data center - regardless of the data size - think billions, trillions of transactions - all processed and conclusions reached - except Fractal.
Fractal broke the mold of central computing control by building entirely self-contained little systems - not applications, systems.
Each one has everything the entire “mesh” or the whole thing - needs to run.
There is the underlying database - nothing like Oracle - every database is customized to the best representation of the data.
There are domain libraries - so the applications are tiny - not burdened with domain knowledge.
Every little Fractal has 100% of the code it needs to run its work - it has, however only some of the data - its buddies in the “mesh” have the rest.
Thus the concept of mesh computing - or a group or entities, each self-contained computing powerhouses, with limited data, coming together to deliver super compute where the data resides - with instantaneous results.
A few weeks ago, we published that a company like Apple could - at a customer who agreed - put a Fractal on every Apple device from a watch to a server and deliver overnight a “virtual data center” likely more powerful than its current Oracle cluster.
That’s mesh computing. Mesh computing is where edge computing is going when it grows up. And it won’t use IBM, Dell or HP to do it.
You don’t need Apple to do it - mesh computing can be done on any computer, from any vendor, tied to those from others and super computing is at hand - without a data center.
Instantly, one has a virtual data center dwarfing the one it pays handily to run - or one has an internal cloud that dwarf’s Amazon - and it has no hardware cost because it’s already there.
As you will see in our Sustainable Computing site, any company can implement this - today - and the need for ripping up Virginia and Pennsylvania farmland for A.I. data centers vanishes.
The Fractal engineers are demonstrating mesh computing - the next step, or leap, beyond edge computing - every week to companies - mostly in the satellite and drone space - but there is a great fit in the edge computing industry.
As Fractal guys sit on the edge industry sidelines, we see edge computing companies - or more likely their product managers - defining the edge in fewer than 3 digits.
Think 30 locations.
The DoD types are thinking of the edge as 10,000 locations, like drones - operating as one - with no central point of control.
The Fractal struggle now - and it is fun, is to try to drag the edge guys thinking the edge is 20 connected data centers - with low margins, zero differentiation, private equity guys on their necks - seeing that the edge is like 10,000 locations, with high margin services, driving multi-billion dollar valuations.
Now edge computing becomes “virtual data centers” which can run the world’s largest A.I. LLMs - without a power hungry, concrete and steel actual data center.
As this internal struggle continues, the question our product managers ask is whether Fractal ought to just quit trying to show the future to the edge guys and just do it ourselves.
FractalComputing Substack is a newsletter about the journey of taking a massively disruptive technology to market. We envision a book about our journey so each post is a way to capture some fun events.
Subscribe at FractalComputing.Substack.com
Fractal Website: Fractal-Computing.com
Fractal Utility Site: TheFractalUtility.com
Fractal Government Site: TheFractalGovernment.com
Fractal Sustainable Computing: TheSustainableComputingInitiative.com
@FractalCompute
Portions of our revenue are given to animal rescue charities