



For A.I. Applications – How You Store Data Matters
Relational database is dead


How You Store And Traverse Data Matters in A.I.
If you can make the physical data storage match the way it is processed, you can hyper-optimize the unit of work.
Fractal Engineering June 2024
The future of artificial intelligence applications is tied to speed and scale – both of which are thus its constraints.
Current database technology was built before artificial intelligence was a contender – so, there is little to nothing in it that is optimized to make A.I. perform well.
Below is a comparison chart showing the scale of growth from current CRM/billing/corporate applications to A.I. driven decisioning systems making critical, real time judgments.
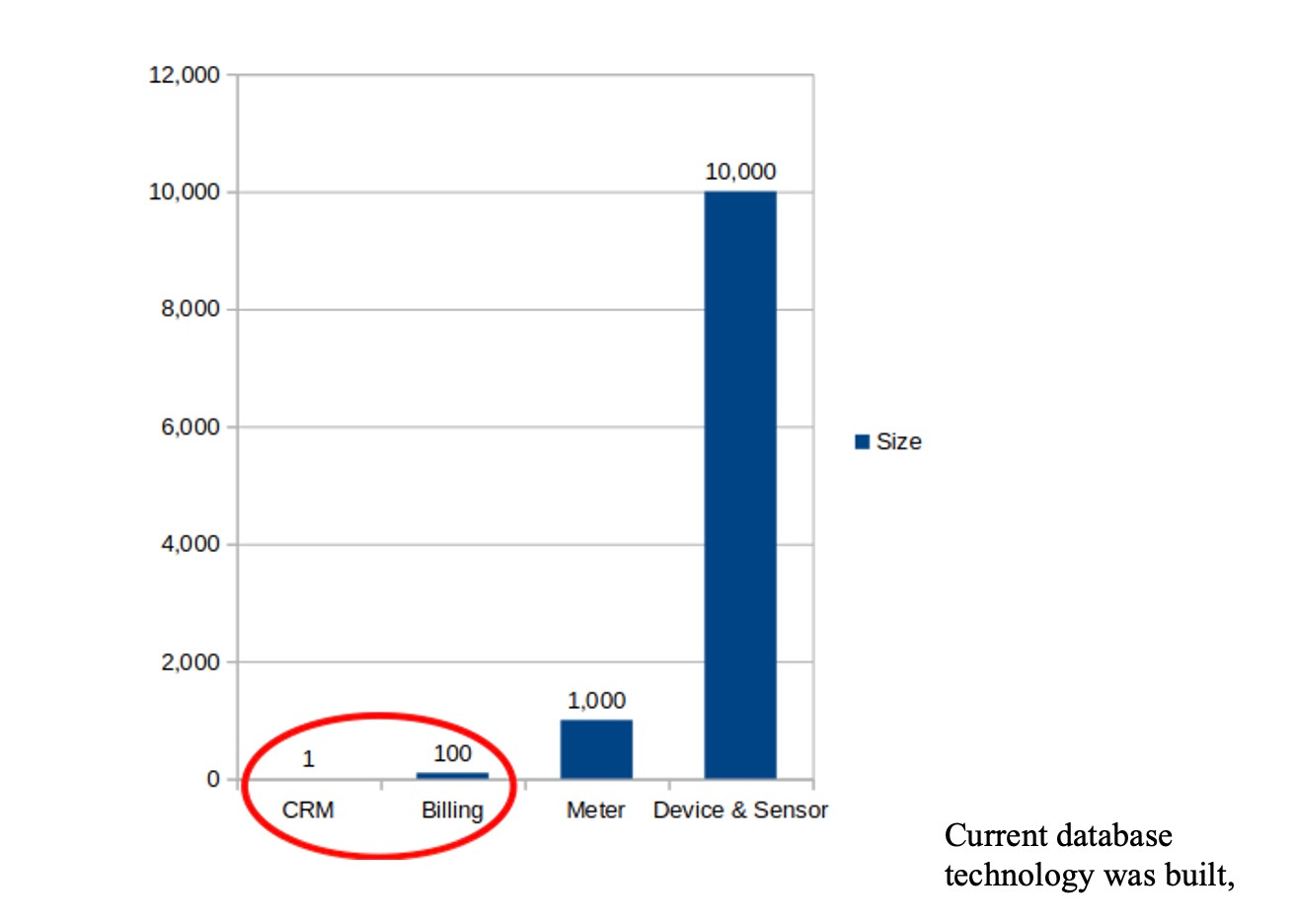
On the left, it shows a large CRM system (customer relationship management) set to a unit of 1.
By comparison, a firm’s billing system is a 10 in terms of data volume.
Then arrives the future – data being collected by meters, drones, visualization, devices and sensors – which need to be processed instantly.
Current database technology was built, in the 1980s, to handle CRM, billing, and HR systems which are on a tiny scale compared with the demands of event-driven, sensor/meter systems being deployed for A.I. applications today.
Relational databases are I/O heavy systems that choke on even small A.I. applications.
In the early days of database technology, we hand-coded high performance custom databases which stored data so that it could be natively processed by specific applications.
The good news was such systems performed with spectacular efficiency – they used small amounts of computer power and ran lightning fast.
The bad news was we had to laboriously build a new database engine for each application.
How one stores the data matters when speed, efficiency, power usage and data center size become constraints.
Those are the constraints today – constraints because obsolete relational technologies are trying to force A.I. systems to use their 1980s approach to database design.
A.I. running on the databases found in most data centers does not scale well – there is not the energy available to build more data centers – citizens are getting miffed that data centers are spoiling the landscape – you get it.
An alternative is to custom build a bespoke database engine for every new A.I. application, just like we did in the "old days" – so they run fast, use little power, and do not require massive data center deployments.
Between that Hobson’s choice lies the Fractal architecture.
Fractal dealt with this problem years ago and took the time to build in its tech stack a database layer adaptable to the application and data at hand.
Fractal’s core belief is that data must be stored and traversed as close as possible to how it is going to be processed by an application – which requires multiple capabilities.
The first is the ability to apply a columnar data structure, a relational one, document or any of a host of other database storage and computational architectures which BEST fit the data and the application.
More than one such database architecture type can be used in the application to match the different processing tasks of the application.
Fractal applies databases that fit how the data is processed rather than force the data into whatever tool is at hand.
In addition, Fractal goes a step, a pretty big one, farther.
Fractal uses A.I.-driven sharding and partitioning to physically store the data in a manner which optimizes how each A.I. agent will process every unit of work.
This has the added benefit that database complexity is significantly reduced which speeds up application development.
For example, in a recent case, a billing system was moved to Fractal.
The legacy, relational system had 650 tables – and required a data center to process.
When moved to Fractal, data was reduced to a handful of tables – which any application developer could easily understand and thus tremendously sped up application development.
The resulting application was also efficient enough that it did not require a data center, or cloud deployment, and was therefore much less expensive to operate.
Currently the Fractal team is working with development teams who need to collect massive electric utility meter, sensor, and device data and reason over it with AI agents.
The Fractal engineers are also working with some government contractors on how to deliver nearly instantaneous computing – across thousands of drones, with no data center, delivering swarm computing – likely the next thing beyond edge computing.
When data is organized and stored in a way that is in sync with how it will be processed, entirely new A.I. applications become not just possible – they become possible at scale.
And in A.I., he who has the scale, prevails.
FractalComputing Substack is a newsletter about the journey of taking a massively disruptive technology to market. We envision a book about our journey so each post is a way to capture some fun events.
Subscribe at FractalComputing.Substack.com
Fractal Website: Fractal-Computing.com
Fractal Utility Site: TheFractalUtility.com
Fractal Government Site: TheFractalGovernment.com
Fractal Sustainable Computing: TheSustainableComputingInitiative.com
@FractalCompute
Portions of our revenue are given to animal rescue charities.
Mr. Jay, every time I read one of your newsletters I'm reminded of the cinematic meeting between the actors playing the characters of Boston Red Sox owner John Henry and Oakland A's GM Billy Beane in the movie "Moneyball." John Henry's character describes how ANY legitimate large-scale improvement is resisted and fought-against by those whom the improvement most threatens. There is no good reason to resist the improvements offered by your company. With their resistance to the obvious benefits your company offers, more than a few leaders in business & government reveal more than they are aware about themselves.
Relational will likely never die, but it will (has?) fallend from dominance. Absolutely. Oracle 23ai has some very adaptive features (vector, column, relational, graph, yada) along these lines.
Time for me to admit ignorance -- how does fractal differ from map/reduce hadoop, 'co-locate the compute and data'? How are re-shardings and cross node latencies reduced or avoided? And where on Earth does one find their Careers page?
Genuine interest, not pushback. Am sold enough to want to know a lot more...